The blog series ‘From the Engine Room’ is dedicated to the technical aspects and challenges of the ‘Edition der fränkischen Herrschererlasse’. Unlike our other academic articles on findings and editorial insights, here we focus on the infrastructural, methodological and technological dimensions of a long-term digital project. Since 2014, we have been working on a new edition of the capitularies. Designed as a hybrid edition, the project poses particular challenges for us: How can we ensure the long-term availability of our research data? How can we belatedly integrate measures for implementing the FAIR principles into a work plan that was designed before their establishment? How can we network effectively with other projects and infrastructures? Or what role could AI play in the project? In shorter articles, we examine these questions from different perspectives: from research data management and networking strategies to technical infrastructure and the use of new technologies. In doing so, we share not only ideas and solutions, but also open questions and desiderata.
Introduction
Digital edition projects do not operate in a vacuum. Networking with other projects, databases and infrastructures is becoming increasingly important – not only for visibility, but also for the functionality and reusability of research data. For Capitularia, this raises a fundamental question: Which networking activities are worthwhile, and how can the effort involved be justified?
The DELM network: International networking of early medieval manuscript databases
The international network ‘Databases of Early Latin Manuscripts’ (DELM) is an association of databases and edition projects related to early medieval manuscripts. Capitularia, like its ‘little sister’ Bibliotheca legum, has been an active member of this network from the very beginning. The network, which was founded by Immo Warntjes (Trinity College Dublin) and Pádraic Moran (University of Galway) in 2023/2024, provides a platform for exchange between the participating projects and researchers, who inform each other about developments and work progress and collaborate (in thematic working groups) on solutions to common challenges (e.g. harmonised dating information).
In the context of DELM, Pádraig Moran also developed a lookup or ‘see also’ service that uses simple means to link information on manuscripts across various resources. The service allows users to search for manuscripts and find corresponding entries in Capitularia, the Bibliotheca and other DELM databases. Currently (as of 10/2025), data from the following nine databases and projects has been included, with more sure to follow:
- Bibliotheca Legum
- Capitularia
- Clavis Canonum – Selected Canon Law Collections, ca. 500–1234
- Computus in the Carolingian Age
- Descriptive Handlist of Breton Manuscripts, c. AD 780–1100
- Earlier Latin Manuscripts
- Foundations of Irish Culture
- Innovating Knowledge
- Manuscripts with Irish Associations
This helps researchers to quickly see which projects mention a particular manuscript, so that relevant sources of information are gathered in one central location. These links from the service to the individual entries in the projects are based on the numbers from Bernhard Bischoff’s Katalog der festländischen Handschriften (Catalogue of Continental Manuscripts) and E. A. Lowe’s Codices Latini Antiquiores. Agreeing on this foundation is not without certain difficulties, as the numbers are not authority data in the strict sense and, for example, Bischoff sometimes lists related manuscripts under one number, while composite manuscripts can have several numbers, leading to n:n relationships that cannot be clearly resolved. However, there are plans to expand the service, e.g. to include references to the Handschriftenportal and similar national projects. All data and tools of the DELM network are documented and reusable on GitHub.
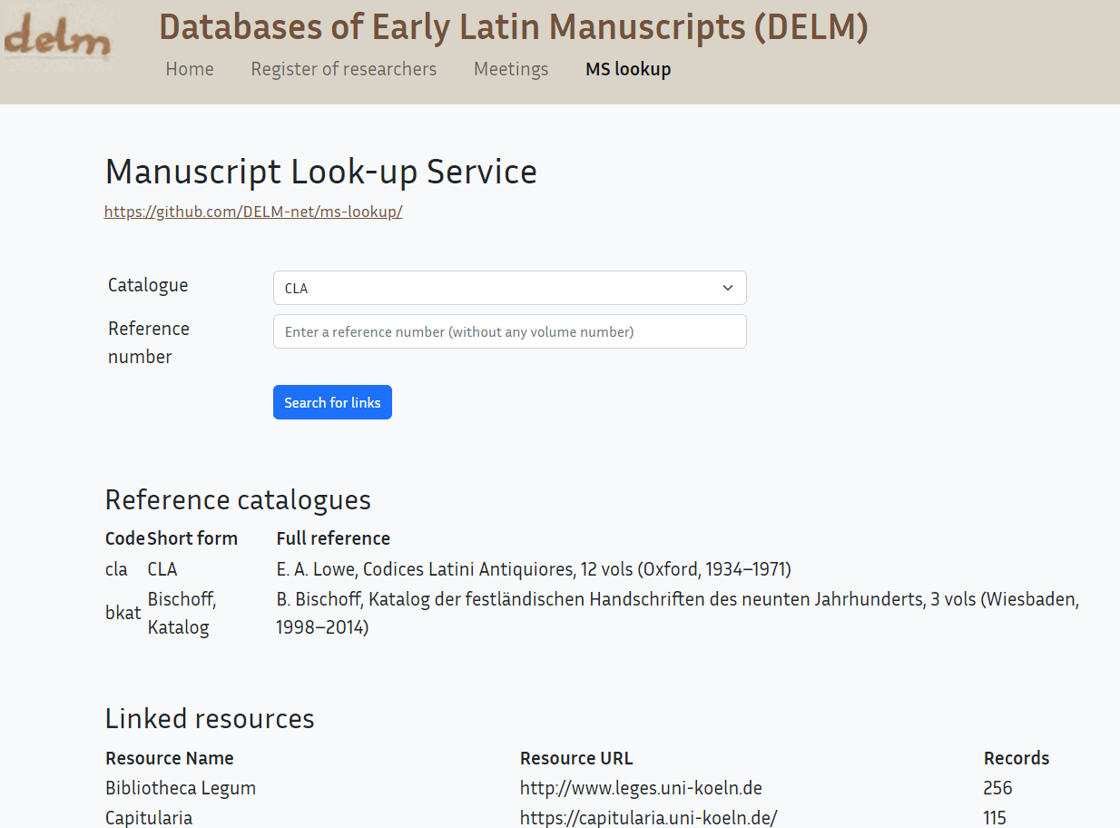
Participation in DELM creates added value on various levels and for multiple parties: users are offered centralised access to normally distributed information sources, which also supports comparative research; the project gains greater visibility in the international research community; cooperation is promoted and joint problem solving is facilitated.
The costs, on the other hand, are relatively low: the lookup service is developed and maintained by our colleagues in Ireland. Preparing our data for import into the lookup service was quite straightforward, as the required information was already contained in our encodings and could therefore be transformed into the specified format, a deliberately basic structured CSV file, using simple scripting. This file only contained the columns Catalogue Code (bkat for the Bischoff catalogue and cla), Reference Number (the corresponding numbering) and URL, i.e. the link to the relevant manuscript in our own database. Unless further manuscript descriptions are added, e.g. due to new discoveries, or the links change for any reason, it is not necessary to update the source data.
The frequency of network meetings is rather low, so no significant time commitment is required. The network has also grown steadily since its inception, which means that presentations on individual work progress tend to be short in favour of covering a broad range of topics and are always voluntary. The working groups modularise and structure the work as effectively as possible. Since these are topics and challenges that the projects have to deal with anyway, the joint exchange tends to reduce the amount of work that would otherwise have to be invested individually. Another added value can also lie in the fact that, depending on the context, appearing as an international network has a greater impact than just one individual project.
Text+ and the NFDI: Structural integration into the national research data infrastructure
Through the CCeH as the technical partner of the project and currently also through a matrix position, Capitularia is closely linked to the Text+ consortium as part of the German National Research Data Infrastructure (NFDI). Regarding its scope, Text+ is focused on the sustainable preparation, provision and preservation of text- and language-based research data and aims at constructing a flexible and scalable research data infrastructure able to cater to the unique requirements of academic disciplines that work with those data. It is organized along the three data domains collections, lexical resources, and editions.
The institutional link between project and consortium provides direct access to a wide range of resources and, above all, expertise. Like other NFDI consortia, Text+ offers training and consulting on RDM as well as other topics, technical services and support. These services are available to the general public. However, our participation as a ‘data contributor’ and project, which – due to personnel overlaps – belongs to the “inner circle”, is more direct and includes the presentation of the project, e.g. at events such as the NFDI local forums or on the consortium’s publication and dissemination platforms (e.g. in the blog series Ressourcen-Reigen).
Conversely, we also contribute to guidelines or recommendations based on the experience we have gained in the project, or use our expertise to advise other, similar projects. This ‘collegial’ assistance is not limited to the context of Text+, of course, but also takes place on a wider scale.
Participation in activities (both active and passive) naturally requires human and time resources. However, this investment pays off through the knowledge transfer and structural support that results from it. Especially in a highly dynamic field such as digital editing, it seems important to stay up to date with current developments, and to engage in regular training. Only then can one’s own digital editorial activities be adequately reflected upon. This also speaks in favour of active participation in (still) current discourses on topics such as standardisation, data quality and interoperability. The exchange of ideas on these topics both helps to make informed decisions for oneself and one’s own projects and also contributes to the development of best practices.
Academies’ Programme: Networking at institutional level
As part of the Academies’ Programme, Capitularia is integrated into a structure that supports long-term projects spanning decades. This institutional framework offers a comparatively high degree of predictability and reliability thanks to long-term funding structures. However, this is offset by a problem that is particularly relevant to long-term projects: future developments, whether technical or political, can only ever be predicted to a limited extent, which makes project planning from scratch and all decisions for the future more difficult. The academies are well aware of these problems and their (shared) responsibility and are trying to take appropriate measures. The majority of them are also actively involved in the NFDI consortia.
With their own research information system AGATE, they are endeavouring to describe all projects funded by the Academies’ Programme (both completed and ongoing) in accordance with current standards and to make the aggregated metadata available to others via interfaces. The portal is also equipped to record ‘research resources’ (= project results in the sense of data) in a structured manner.
In particular, the AG eHumanities (under the auspices of the AWK NRW) in the Academies Programme strives to promote the exchange of experience between academy projects through regular offers and events (e.g. currently a workshop on the topic of “Data Perspectives “). There are also many initiatives within the medieval academy projects themselves to improve networking in order to jointly address the challenges faced by long-term projects. This exchange usually takes place informally, but also within the framework of joint events, and concerns, for example, the preparation and provision of data, such as our transcriptions for use as training material for LLMs or information enrichment.
Conclusion:
Even though the effects of networking activities can only be measured to a very limited extent and naturally involve considerable effort, we are convinced that our commitment in this area pays off (e.g. through increased visibility). How much time and human resources should be invested must, of course, be weighed up on a case-by-case basis. For future project proposals, it may be useful to calculate not only the (time and financial) costs of further training and conference participation, but also those of networking activities as realistically as possible in advance and to take them into account in the work plans, as these costs should not be underestimated.
Daniela Schulz
November 2025
References:
B. Bischoff, Katalog der festländischen Handschriften des neunten Jahrhunderts, 3 vols (Wiesbaden, 1998–2014)
E. A. Lowe, Codices Latini Antiquiores, 12 vols (Oxford, 1934–1971)
DELM Network: Databases of Early Latin Manuscripts. https://delm-net.github.io/
GitHub DELM ms-lookup: https://github.com/DELM-net/ms-lookup
Text+ Datendomäne Editionen: https://text-plus.org/ueber-uns/arbeitsbereiche/editionen/