Die Blogreihe „Aus dem Maschinenraum“ widmet sich den technischen Aspekten und Herausforderungen der „Edition der fränkischen Herrschererlasse”. Anders als unsere bisherigen wissenschaftlichen Beiträge zu Funden und editorischen Erkenntnissen, fokussieren wir uns hier auf die infrastrukturellen, methodischen und technologischen Dimensionen eines digitalen Langzeitprojekts. Seit 2014 erarbeiten wir eine Neuedition der Kapitularien. Als Hybridedition konzipiert, stellt uns das Projekt vor besondere Herausforderungen: Wie gewährleisten wir die langfristige Verfügbarkeit unserer Forschungsdaten? Wie können wir nachträglich Maßnahmen zur Umsetzung der FAIR-Prinzipien in einen Arbeitsplan integrieren, der vor deren Etablierung konzipiert wurde? Wie vernetzen wir uns sinnvoll mit anderen Projekten und Infrastrukturen? Oder welche Rolle könnte KI im Projekt spielen? In kleineren Beiträgen beleuchten wir diese Fragen aus unterschiedlichen Perspektiven: vom Forschungsdatenmanagement über Vernetzungsstrategien bis hin zur technischen Infrastruktur und dem Einsatz neuer Technologien. Dabei teilen wir nicht nur Ideen und Lösungsansätze, sondern auch offene Fragen und Desiderata.
Einleitung
Die rasanten Entwicklung von KI-Technologien der letzten beiden Jahre und deren zunehmende Durchdringung auf vielen Ebenen wirft Fragen auf: Welche Potenziale bieten diese Technologien für Editionsprojekte? Wo liegen ihre Grenzen? Und wie positioniert sich Capitularia in diesem Spannungsfeld? Der nachfolgende Post skizziert den aktuell im Projekt genutzten Tool-Stack und erklärt, warum bislang keine KI-Tools oder Methoden im Workflow vorgesehen sind, aber auch, wo wir dahingehende Potenziale sehen.1
Capitularia Tool Stack und Workflow
Im Kapitularienprojekt setzen wir bisher ganz bewusst auf manuelle Transkription und Nachkollationen im oXygen XML Editor, regelbasierte Kollation (basierend auf CollateX) und traditionelle editorische Standards. Die Gründe liegen hier einerseits in der “Vorzeitigkeit” des Projektes, dessen Konzeption und Beantragung in eine Zeit zurückgeht, in denen die heute verfügbaren und z.T. etablierten Tools noch gar nicht existierten oder noch in den Kinderschuhen steckten. Andererseits, und das sind vermutlich die gewichtigeren Aspekte, liegen sie in den zu edierenden Materialien begründet. Die Überlieferungssituation der Kapitularien erklärt, warum Tools, die in anderen Projekten gewinnbringend eingesetzt werden, hier an ihre Grenzen stoßen:
- Die Kapitularien-Texte sind meist vergleichsweise kurz, verteilt in Sammlungen mit heterogenem Inhalt. Oft wurden die Kapitularien von mehreren Händen auf engem Raum geschrieben.
- Zwar existiert mit knapp 400 Handschriften eine recht bedeutende Menge an Überlieferungsträgern, doch sind die Kapitularien sehr unterschiedlich breit überliefert und vereinzelt auch fragmentiert.
- Bei Kapitularien handelt es sich um normative Texte, die Regelungen und Bestimmungen enthalten, nicht um narrative Texte mit zahlreichen Personen- oder Ortsnennungen.
- Im Rahmen des Projektes wird aus Kostengründen – sofern vorhanden und von ausreichender Qualität – auf existente Digitalisate zurückgegriffen. Hier handelt es sich mitunter aber auch um ältere s/w-Scans, nicht um hochauflösende Aufnahmen.
Nun funktioniert Handwritten Text Recognition (HTR) mit Tools wie Transkribus aber am besten mit großen Mengen konsistenter Trainingsdaten und längeren, zusammenhängenden Texten von wenigen Schreibern. Zwar sind die meisten Kapitularien in karolingischer Minuskel geschrieben – eine Schrift, für die in Transkribus ein Modell existiert, doch gibt es in der Überlieferung auch durchaus frühere sowie weit spätere Textzeugen. Insgesamt ist anzunehmen, dass die Verwendung bestehender Modelle bei den kurzen und divers im Sammlungskontext überlieferten Texten zu vergleichsweise hohen Fehlerquoten führen würde. Die Nachbearbeitung würde also vermutlich länger dauern als die Transkription. Dabei ist auch zu bedenken, dass nicht zu allen Handschriften hochauflösende Digitalisate zur Verfügung stehen und die Qualität der Digitalisate determiniert ebenfalls die Quote korrekt erkannter Buchstaben oder Kürzungen. Aus diesem Grund scheint der aktuelle Workflow, der manuelle Transkription gefolgt von zwei vollständigen Nachkollationen (6-Augen-Prinzip) durch geschulte Mitarbeiter:innen vorsieht, alternativlos. Die hohe Qualität und philologische Sorgfalt, die so erreicht wird, könnte HTR nicht ohne erhebliche Nachkontrolle und Nachbearbeitung leisten.
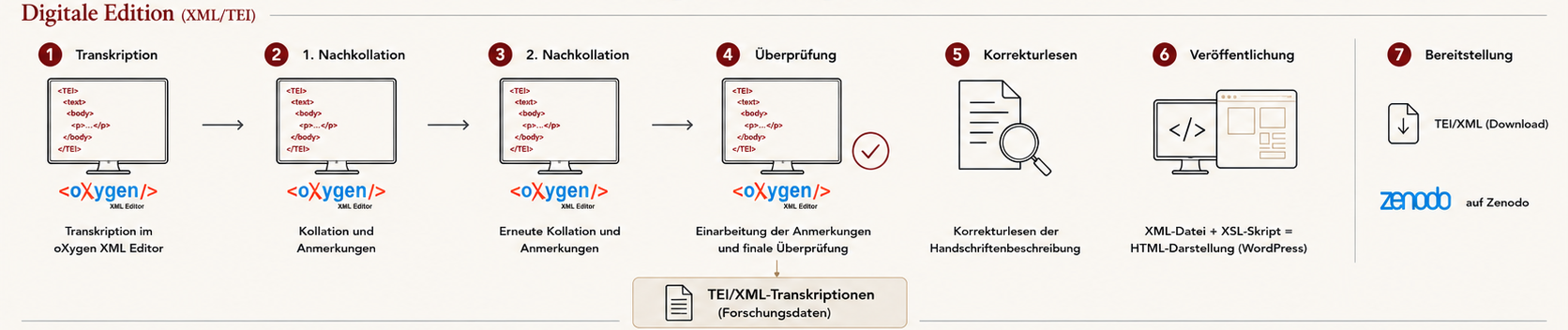
Workflow der Digitalen Edition (eigene Darstellung; erstellt mit Hilfe von ChatGPT)
Eine weitere im editorischen Kontext mittlerweile recht etablierte Methode ist Named Entity Recognition (NER), da dies beispielsweise Registererstellung und folglich Normdatenverknüpfung erleichtert. Wie erwähnt, werden in Kapitularien – mit Ausnahme der jeweiligen Herrscher – allerdings kaum konkrete Personen oder Orte genannt. Hinzu kämen hier auch noch die Probleme, die mit historischen Ortsnamen und deren Verortung einhergehen. Welche Person oder welcher Ort bzw. welches Gebiet gemeint ist, lässt sich nur durch tiefes historisches Wissen klären. Die Identifikation und Disambiguierung von Named Entities bleibt damit eine intellektuelle, editorische Tätigkeit, die in unserem Kontext nicht automatisiert werden kann.
Und auch bei Anwendungen, die Mehrwerte oder Zeitersparnis versprechen, bleibt deren Einsatz kritisch zu hinterfragen. Nach 12 Jahren haben wir bewährte und etablierte Workflows. Die nachträgliche Integration neuer Tools würde einen erheblichen Aufwand bedeuten – bei eher unsicheren Mehrwerten. Dazu kommen generelle wissenschaftliche, aber auch ökologische Bedenken: KI-Tools gewährleisten keine Transparenz und Reproduzierbarkeit und es verbleibt oftmals unklar, wie ein Ergebnis zustande gekommen ist. Auch die zugrundeliegenden Daten sind – bei kommerziellen Modellen – hinsichtlich ihrer Provenienz und Qualität potenziell zweifelhaft. Deren Verwendung führt zu Abhängigkeiten, die aus Projektsicht natürlich nicht erwünscht sind. Seitens der Universitäten ist der Einsatz kommerzieller Modelle und Anbieter offiziell häufig auch schlichtweg verboten. Die notwendigerweise angebotenen offenen Alternativen sind jedoch vergleichsweise beschränkt und bleiben in der Qualität der Ergebnisse hinter den “Großen” zurück. Ebenfalls ist häufig auch der Zugang zu entsprechenden Rechenkapazitäten z.B. für das Training eigener Modelle beschränkt.
Potenzielle Nutzungsszenarien von Anwendungen oder Methoden
Nachfolgend sollen nun einige Überlegungen angestellt werden zu der Frage, wo für uns Potenziale im Einsatz von KI liegen könnten. Dabei ist es wichtig zu erwähnen, dass aus grundsätzlichen Erwägungen nur Anwendungen in Betracht gezogen werden, die nach dem Human-in-the-loop-Prinzip arbeiten, bei denen der Mensch in den Arbeitsprozess eingebunden ist, diesen auf Fehler kontrolliert und die Entscheidungen trifft. Anwendungen können den folgenden Ebenen zugeordnet werden:
- Nutzung im editorischen Workflow (Tools)
- Nutzung in der Interaktion mit Nutzenden (ChatBot)
- Bereitstellung von AI-ready Daten
CTE2TEI
Grundlage für die Erstellung der kritischen Edition im Classical Text Editor (CTE) sind die in TEI/XML-kodierten Handschriftendateien. Das auf CollateX basierende Kollationstool unterstützt die Textkonstitution durch die dynamische Anzeige von Abweichungen und Varianten zwischen den Handschriften. CollateX funktioniert dabei regelbasiert. Die Bearbeiter:innen der einzelnen Texte erstellen den kritischen Text, Variantenapparat, Sachanmerkungen und Übersetzung im CTE. Sie bereiten damit die Druckausgabe, die in der leges-Reihe der MGH erscheint, bestmöglich vor.

Workflow Printedition (eigene Darstellung; erstellt mit Hilfe von ChatGPT)
Die gedruckte Ausgabe wird nach einer Embargo-Frist seitens der MGH für die Nutzung im Kontext ihres Online-Angebots dmgh.de aufbereitet. Natürlich wäre es wünschenswert, wenn der kritische Text mit Übersetzung auch auf der Capitularia-Webseite zur Verfügung stünde und damit auch über die Suche angesteuert werden könnte. Dies würde digitale und gedruckte Edition deutlich enger miteinander verknüpfen. Grundsätzlich bietet der CTE Exportformate an. Es hat sich jedoch in früheren Versuchen herausgestellt, dass diese vereinzelt verlustbehaftet sind, was sehr aufwändige Nachkontrollen notwendig macht. Die Arbeit mit der CTE-Datei selbst, würde die Gefahr von Verlusten in der Transformation zu Exportformaten ausschließen. Ein Ansatz, der daran anschließen würde, wäre eine KI-gestützte Rekodierung z.B. mittels eines Transformer-Modells. Dies würde die digitale Publikation des kritischen Textes erheblich beschleunigen. Die Dateien sind nach einem einheitlichen Template gefertigt, sodass es leicht fallen sollte, Einträge in den Apparaten zu erkennen und in die entsprechende TEI-Struktur (<app>, <lem>, <rdg>) zu überführen. Das Gleiche gilt für Emendationen. Es handelt sich dabei nicht um eine “kreative” Arbeit, sondern um eine schlichte Rekodierung, die klaren Regeln folgt, sodass die editorischen Standards nicht gefährdet würden. Erste Versuche, die aber vom Abbild der gedruckten Ausgabe ausgehen, sind durchaus vielversprechend.
Ein potenzieller Workflow könnte sich wie folgt darstellen:
CTE-Export (kritischer Text)
↓
Spezialisiertes Transformer-Modell
↓
TEI-XML (automatisch rekodiert)
↓
Manuelle Überprüfung durch Editor:innen
↓
Digitale Publikation + Webausgabe
Weitere Szenarien
Neben der Rekodierung gibt es noch andere Bereiche:
- Auf der Ebene der Nutzendeninteraktion könnte ein Retrieval-Augmented Generation (RAG)-gestützter Chatbot über die Inhalte hinweg Fragen wie “Welche Kapitularien regeln Klostereigenschaften?” beantworten. Dies wäre eine Ergänzung zur bislang existierenden Volltextsuche als intelligente Suchoberfläche über die bereits editierten Texte. Überlegungen zur Umsetzung eines solchen Chatbots gibt es beispielsweise im befreundeten Projekt “Burchards Dekret Digital“.2
- Sprachmodelle könnten helfen, Kollationsergebnisse oder Variantenhistorie nutzerfreundlicher darzustellen bzw. auch Sammlungen oder Cluster von Kapitularien in den Überlieferungsträgern sichtbar machen. Explorative Visualisierungen könnten für die Bearbeitenden eine Hilfe sein, um Hypothesen zur Verteilung und Abhängigkeiten zwischen Textzeugen zu prüfen, für Nutzende könnten Visualisierungen der besseren Vermittlung dienen.
- Aus der “Provider”-Perspektive könnten die Transkriptions- und Editionsdaten AI-ready aufbereitet werden, um so für verschiedene Anwendungen und Forschungsfragen (beispielsweise im Kontext von Natural Language Processing, NLP) nutzbar gemacht werden zu können. Sie könnten damit auch Teil der aktuell in Entstehung begriffenen Wissensgraphen werden. Hier stellt sich allerdings die Frage der Zuständigkeit: wir stellen unsere Daten ja bereits unter einer entsprechenden Lizenz zur Nachnutzung zur Verfügung, z.B. über Zenodo. Ist es nun auch unsere Aufgabe, die Daten für die Nachnutzung (also AI-ready) aufzubereiten oder liegen die Zuständigkeiten bei jenen, die die Daten nutzen möchten? Was würde eine Aufbereitung ganz konkret bedeuten? Hier ist zu bedenken, dass dafür bei uns keine entsprechenden Arbeitspakete vorgesehen sind und demnach auch keine Ressourcen vorhanden. Andererseits ist es aber auch der Anspruch eines Akademieprojektes, hier evtl. eine Vorreiterrolle einzunehmen. Vermutlich wäre eine Aufbereitung auch im größeren Kontext der Akademieprojekte denkbar, sodass die Last hier nicht beim einzelnen Projekt läge, sondern Synergien möglich wären.

Potenzielle Einsatzbereiche für kontrollierten KI-Einsatz (eigene Darstellung; erstellt mit Hilfe von ChatGPT)
Zusammenfassung
Wir verzichten aktuell nicht aus Prinzip auf KI-Anwendungen, sondern aus pragmatischen Erwägungen: die Überlieferungssituation, unser Textmaterial und die bestehenden Workflows machen übliche Tools wie Transkribus für uns nicht rentabel. Gleichzeitig sehen wir aber auch reale Potenziale. Vor allem die Rekodierung der kritischen Texte mittels KI-Modellen erscheint als vielversprechendes Szenario, erweiterte Suchmöglichkeiten, Visualisierungen und AI-ready Datenaufbereitung sind weitere Felder.
Es erscheint uns nicht sinnvoll, zwischen “Ja zu KI” oder “Nein zu KI” zu wählen, sondern für jede Aufgabe neu zu entscheiden, ob ein Mehrwert vorliegt und der Einsatz wissenschaftlich, ressourcentechnisch und ökologisch zu verantworten ist. Wenn KI zum Einsatz kommt, geschieht dies selektiv und transparent. So ist, wie man auch in diesem Post sieht, die Gestaltung von Infographiken und Visualisierungen für z.B. Präsentationen und Poster durch die neuen Möglichkeiten doch deutlich einfacher geworden.
[1] Der Beitrag basiert grundlegend auf einem im Dezember 2025 gehaltenen Vortrag beim Workshop “Digitale Editionen der Zeitgeschichte zwischen KI und Linked Open Data” (Berlin, 04./05.12.2025) der Kommission für Geschichte des Parlamentarismus und der politischen Parteien (KGParl). Eine PDF-Version der Präsentation ist auf Zenodo verfügbar.↑
[2] Cf. Daniela Schulz (8. Mai 2025). Edit empfiehlt #3: Burchards Dekret Digital (Ressourcen-Reigen Spezial). Text+ Blog. Abgerufen am 25. Juni 2026 von https://doi.org/10.58079/13w6w↑
Weiterführende Literatur zum Thema:
- Gerrit Brüning: Digitale Editionen von Goethes Werken seit 1998. Bilanz und Perspektiven in Zeiten Generativer KI. In: Daniela Schulz / Marcus Baumgarten / Torsten Schaßan (Hg.): Digitales Edieren gestern, heute und morgen (= Zeitschrift für digitale Geisteswissenschaften / Sonderbände, 7). Wolfenbüttel 2025. 30.12.2025. HTML / XML / PDF. DOI: 10.17175/sb007_002
- Christopher Pollin / Franz Fischer / Patrick Sahle / Martina Scholger / Georg Vogeler: When it was 2024 – Generative AI in the Field of Digital Scholarly Editions. In: Zeitschrift für digitale Geisteswissenschaften 10 (2025). 10.07.2025. HTML / XML / PDF. DOI: 10.17175/2025_008
- Michael Schonhardt: Do One Thing and Do It Well. Vier Prinzipien einer digitalen Editionspraxis im Spannungsfeld zwischen fachlichen Standards und Deep Learning. In: Daniela Schulz / Marcus Baumgarten / Torsten Schaßan (Hg.): Digitales Edieren gestern, heute und morgen (= Zeitschrift für digitale Geisteswissenschaften / Sonderbände, 7). Wolfenbüttel 2025–2026. 05.03.2026. HTML / XML / PDF. DOI: 10.17175/sb007_005
- Daniela Schulz (2025): Potenziale und Herausforderungen des (digitalen) Edierens. Die „Edition der fränkischen Herrschererlasse”. In: DigiTRiP. https://doi.org/10.58079/13r7m